Aujourd'hui, la voiture individuelle est le mode privilégié de déplacement. Cela pose de nombreux problèmes de santé publique (pollution de l'air, inactivité, pollution sonore...) et environnementaux (pollution des sols et de l'eau, réchauffement climatique...).
Ces dernières décennies, nous avons aménagé nos villes autour de la voiture, avec la séparation des finalités (travail, logement, consommation...) et l'étalement urbain. Le projet de recherche consiste à qualifier l'adéquation de l'environnement urbain avec les mobilités actives dont la marche.
Dans un premier temps, nous évaluons le niveau d'opportunités (commerces, services, emplois...) accessibles à pieds depuis chaque rue comme prérequis au choix d'un déplacement pédestre. Pour ce faire, nous avons mené un travail de synthèse des données géolocalisées disponibles en accès ouverts et fournies par des acteurs publics tels que l'IGN (Institut Géographique Nationale) ou la plateforme opendata france et participatifs tels que OpenStreetMap.
Il en résulte la carte (et une méthodologie) que nous vous proposons de découvrir ci-dessous.
Présentation de la carte
Lecture de la carte
Chaque rue est colorée selon un score qui traduit un niveau d’accès à des opportunités (commerces, services…) pour des déplacements à pieds sans prise en compte du dénivellé.
Un score sera d’autant plus élevé que les services seront proches, nombreux et d’une capacité importante (un supermarché offre une plus grande diversité de services qu’un cordonnier par exemple).
A noter que pour chaque ville, catégorie et niveau de mobilité, un même nombre de rues est distribué dans chaque rang de score ce qui facilité la lecture des résultats mais empêche de comparer les valeurs absolues des scores entre 2 villes par exemple (autrement dit les scores sont relatifs à un lieu/catégorie/niveau de mobilité).
Précision : les rues en noires contribuent aux calculs de score mais leurs propres résultats sont invalides car leur “zone de chalandise” se situe partiellement en dehors de la zone d’étude.
Options
Le score est proposé pour une dizaine de grandes villes françaises accessibles via le menu déroulant. Il est également possible d’afficher un score pour une catégorie de services parmi “commerces”, “emplois”, “divertissements”, “études”, “santé/administratif”…
L’option de “niveau de mobilité” modifie la pénalité appliquée avec l’éloignement du service ce qui permet de favoriser encore plus la proximité pour une mobilité “réduite”.
Les points d’intérêt sont consultables en demandant l’affichage des “opportunités”. Les cercles qui apparaissent sont colorés selon la catégorie d’appartenance du service et sa taille rapporte son importance (4 tailles pour les ordres de grandeur 1, 10, 100 et 1000+). Un survol des points avec la souris expose leur identité ainsi que le niveau de service qui leur est attribué avant pondération par l’éloignement.
Analyse
Les lieux évalués sont centrés sur les mairies des plus grandes villes françaises. On retrouve une structure urbaine assez commune d’une ville à l’autre : le centre-ville (ou “hypercentre” dans certaines “métropoles”) concentre beaucoup d’opportunités dans toutes les catégories et la ville se construit en rayonnant depuis ce centre avec certaines contraintes naturelles tels la présence de la mer (Marseille), de montagnes (Grenoble) ou de frontières administratives (Strasbourg).
En périphérie, des zones industrielles abritent de nombreux emplois et commerces, l’offre d’études peut s’organiser en campus tandis que l’offre en divertissements peut se diffuser un peu plus avec toutefois des finalités assez disparates (parcs, restaurants, équipements sportifs) que ne rapporte pas notre niveau d’analyse.
Des centre-bourg ou centres de quartiers ressortent sur les cartes, ils regroupent en général une offre un peu fournie en centres administratifs et lieux de santé. Ces lieux s’articulent souvent autour d’axes très fréquentés par les automobiles et pourraient bénéficier d’efforts prioritaires de piétonnisation de la part des politiques et aménageurs.
Les distances sont évaluées en suivant les voies de cheminement, ce qui fait ressortir certaines circonvolutions qui éloignent les services de leurs potentiels bénéficiaires. Un exemple flagrant apparaît au travers des quartiers pavillonnaires construits autour de la seule mobilité automobile et qui enferment généralement leurs habitants dans ce mode de déplacement.
Nous terminons cette analyse avec cette idée que ces scores d’opportunités rapportent une certaine “efficacité” de la construction de la ville : les personnes habitant dans les rues dotées des moins bons scores dépendront d’autant plus de moyens de locomotion, ce qui signifie une plus grande dépense financière et énergétique pour ce poste avec potentiellement une moindre qualité de vie.
Méthodologie
Hypothèses
Le score est calculé dans le respect des hypothèses suivantes :
- nous considérons des personnes moyennées statistiquement en termes
d’aptitudes physiques et de besoins
- tous les segments de voies ont les mêmes qualités perçues (largeur de
voie, présence ou non de végétation…) et les pentes sont ignorées
- tous les points d’intérêt d’une catégorie ont la même qualité
- nous considérons les mobilités en journée sur un jour moyenné
- nous faisons abstraction des transports en commun
Présentation du score
Le score s’inscrit dans la lignée des travaux sur la mesure de l’accessibilité à des services tels que décrite par la littérature scientifique par exemple dans (Páez et al., 2012).
Ainsi, pour chaque rue de la ville, nous dressons la liste des points d’intérêts (commerce, emploi, service…) accessibles dans une certaine “distance marchable”. Nous attribuons une certaine importance à chacun de ses points d’intérêt.
Le score pour une rue est alors la somme des importances des points d’intérêts environnants pondérées par un coefficient rapportant le déclin d’intérêt avec l’augmentation de la distance.
\[score_{catégorie} = \sum_{k=0}^{destinations} Déclin(distance_k) * Importance_k\]
Importance des points d’intérêt
On attribue aux points d’intérêt une importance liée à leur capacité d’accueil quotidienne.
En effet, chaque jour toutes les personnes d’une aire géographique doivent satisfaire leurs besoins. En considérant une aire géographique suffisamment vaste, on peut approximer que tous les commerces/services et autres “points d’intérêt” satisfont l’ensemble des besoins de la population locale. Nous pouvons ainsi estimer qu’un point d’intérêt satisfait les besoins à hauteur de sa capacité d’accueil (en nombre de personnes) que nous décidons de retenir comme notre paramêtre d’“importance”.
Dans cette étude, nous prenons un ordre de grandeur de fréquentation évalué par nos soins, mais des données plus fines seraient à trouver chez Google par exemple qui propose une valeur d’affluence horaire pour les commerces dans son service cartographique.
Note : le survol de la carte interactive avec la souris affiche les importances attribuées à chaque point d’intérêt
Distance marchable et déclin d’intérêt
Nous considérons une “distance marchable” pour rapporter la dégradation avec l’augmentation de la distance du niveau de service fourni par un point d’intérêt.
L’étude de (Yang & Diez-Roux, 2012) synthétise dans la figure ci-dessous les résultats d’un sondage réalisé aux Etats-Unis auprès de 300 000 personnes ayant réalisé un total de plus de 1 millions de déplacements.

En nous appuyant sur cette analyse, nous considérons une décroissance linéaire de l’attraction d’un commerce/service :
\[Déclin(distance) = 1.0 - \frac{distance}{distance\_marchable}\]
si \(distance \leq distance\_marchable\), sinon \(Déclin(distance) = 0.0\)
Calcul de scores pour différentes finalités de déplacements
Nous avons classé les points d’intérêt en différentes catégories complémentaires afin de calculer un score pour chacune d’elle et rendre le résultat d’autant plus informatif.
Les catégories retenues découlent de l’enquête menée par (INSEE, 2010) pour les
déplacements en France :
- commerces : centres commerciaux, commerces de centre-ville…
- emplois : entreprises avec des employés
- divertissements :
- études : tout établissement d’éducation de l’école primaire à
l’université
- santé/administratif : hopitals, cabinets de médecins, administrations
publiques…
- visites : parents et amis à visiter
L’enquête donne la répartition des déplacements pour chaque catégorie mentionnée précédemment :
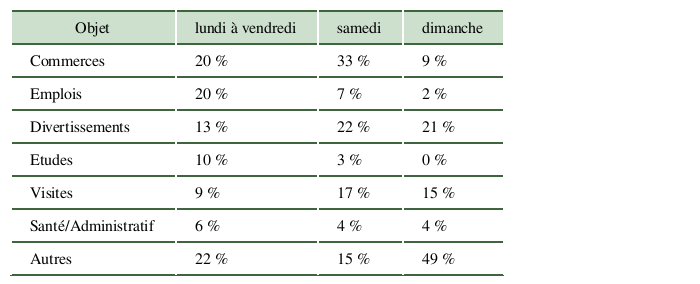
Répartition des déplacements locaux en France (INSEE, 2010)
Ces statistiques sont obtenues en considérant qu’un déplacement commence là où la finalité du précédent déplacement a été atteinte. Les chemins “retours” ne sont pas pris en compte. Les sondés étaient âgés de 6 ans ou plus au moment de l’enquête.
Pour obtenir le score final, on combine les scores par catégorie en une somme pondérée dont les poids sont donnés le tableau précédent :
\[Score_{global} = \sum_{k=0}^{catégories} score\_catégorie_k * poids_k\]
\[poids_k = \frac{5}{7} * p_{jour\_semaine} + \frac{1}{7} * p_{samedi} + \frac{1}{7} * p_{dimanche}\]
Synthèse des résultats
Les scores obtenus sont distribués en quintiles homogènes pour améliorer leur lisibilité. Ces distributions sont réalisées pour chaque ville et chaque distance marchable ce qui produit des scores relatifs au lieu étudié : avec cette approche, il n’est donc pas pertinent de comparer la valeur absolu des scores d’une ville à l’autre (un score B dans une ville peut être aussi bien qu’un score A dans une autre), seules les distributions géographiques sont comparables.
Bibliographie
Implémentation technique et sources de données
Méthodes numériques
En nous inspirant des méthodes de simulation numérique, nous transformons l’équation donnée précédemment pour évaluer les scores d’une catégorie de déplacement dans le calcul suivant :
\[S = A*b\]
avec A la matrice carrée rapportant la perte d’intérêt dans un service avec son éloignement croissant de chaque rue avec chaque rue, b rapporte le vecteur de l’importance des commerces/services par rue et S est le score inconnu.
Traduction algorithmique de l’index
Les étapes pour le calcul du score sont :
- conversion du réseau de voies piétonnes décrivant la ville en
topologie (liste de voisins) de segments de voies
- calcul de la matrice A des coefficients de distance
- attribution d’une importance à chaque point d’intérêt
- classification des points d’intérêt dans les catégories
- projection des points d’intérêt sur les rues (par moindre distance)
pour construire le vecteur b
- calcul de S = A * b pour chaque catégorie de déplacement
- distribution des scores dans des quintiles
- rendu du score sur le réseau de voies pour chaque catégorie
- combinaison des scores en un score global
- rendu du score global sur le réseau de voies
Logiciels
La méthode a été développé en Python avec des algorithmes de calcul SIG (Système d’Information Géographique) de la librairie Geopandas (Jordahl et al., 2020). Les calculs matriciels ont été optimisés par la mise en oeuvre des matrices creuses de Scipy (Virtanen et al., 2020) et les opérateurs d’algèbre linéaire de Numpy (Harris et al., 2020).
Le résultat cartographique est servi par tuiles vectorielles et affiché avec Mapbox GL JS.
Sources de données cartographiques
Le réseau des voies est issu de la BD TOPO de l’IGN. Les points d’intérêt pour la catégories “Visites” sont évalués à partir des empreintes de bâtiments de cette même base. Les points d’intérêt sont extraits d’OpenStreetMap pour les catégories “Divertissements”, “Etudes”, “Commerces” et “Santé/Administratif”. Les points relatifs aux emplois sont tirés de la base de données gouvernementale SIRENE.